最近刚好在学习搜索引擎分词,有了解一些分词插件,在这里给各位猿友分享一下。
本文主要介绍四个分词插件(ICTCLAS、IKAnalyzer、Ansj、Jcseg)和一种自己写算法实现的方式,以及一些词库的推荐。
一、ICTCLAS
1.1、介绍
中文词法分析是中文信息处理的基础与关键。中国科学院计算技术研究所在多年研究工作积累的基础上,研制出了汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System)。
它的主要功能包括中文分词;词性标注;命名实体识别;新词识别;同时支持用户词典。
先后精心打造五年,内核升级6次,目前已经升级到了ICTCLAS3.0。ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,分词正确率高达97.58%(最近的973专家组评测结果),基于角色标注的未登录词识别能取得高于90%召回率,其中中国人名的识别召回率接近98%,分词和词性标注处理速度为31.5KB/s。ICTCLAS 和计算所其他14项免费发布的成果被中外媒体广泛地报道,国内很多免费的中文分词模块都或多或少的参考过ICTCLAS的代码。是一个很不错的汉语词法分析器。
1.2、实例
博主windows64位的,如果32位系统的可参照如下文章:,该文章ICTCLAS的windows32位下载url和实例详解。
如果是windows64位系统,可按照博主的步骤实现实例。
(1)ICTCLAS50-Windows-64下载:
(2)eclipse创建普通的java项目。
(3)ICTCLAS50_Windows_64_JNI解压后,将API目录ICTCLAS文件夹和ICTCLAS_I3S_AC_ICTCLAS50.h复制到java项目的src下。
(4)将API目录除了刚刚的ICTCLAS文件夹和ICTCLAS_I3S_AC_ICTCLAS50.h以外的文件和文件夹都复制到java项目的根目录下。
(5)创建测试类,代码如下:
package com.luo.test;import java.io.UnsupportedEncodingException;import ICTCLAS.I3S.AC.ICTCLAS50;public class Test { public static void main(String[] args) { ICTCLAS50 testICTCLAS50 = new ICTCLAS50(); String argu = ".";//file Configure.xml and Data directory stored. //初始化 try { if(testICTCLAS50.ICTCLAS_Init(argu.getBytes("GB2312")) == false) { System.out.println("Init Fail!"); throw new Exception("初始化错误"); } } catch (UnsupportedEncodingException e1) { // TODOAuto-generated catch block e1.printStackTrace(); } catch (Exception e1) { // TODOAuto-generated catch block e1.printStackTrace(); } String s="中文词法分析是中文信息处理的基础与关键"; //导入用户词典前分词 byte nativeBytes[]; try { nativeBytes = testICTCLAS50.ICTCLAS_ParagraphProcess(s.getBytes("GB2312"), 0, 0); //分词处理 //System.out.println(nativeBytes.length); String nativeStr = new String(nativeBytes, 0, nativeBytes.length, "GB2312"); String[] wordStrings=nativeStr.split(" "); for (String string : wordStrings) { System.out.println(string); } } catch (UnsupportedEncodingException e1) { // TODOAuto-generated catch block e1.printStackTrace(); } }} (6)运行结果:

二、IKAnalyzer
2.1、介绍
IKAnalyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。
从2006年12月推出1.0版开始,IKAnalyzer已经推出 了3个大版本。最初,它是以开源项目Lucene为应用主体的,结合词典分词和文法分析算法的中文分词组件。新版本的IKAnalyzer3.0则发展为 面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。
IK Analyzer 2012特性:
1.采用了特有的“正向迭代最细粒度切分算法“,支持细粒度和智能分词两种切分模式; 2.在系统环境:Core2 i7 3.4G双核,4G内存,window 7 64位, Sun JDK 1.6_29 64位 普通pc环境测试,IK2012具有160万字/秒(3000KB/S)的高速处理能力。 3.2012版本的智能分词模式支持简单的分词排歧义处理和数量词合并输出。 4.采用了多子处理器分析模式,支持:英文字母、数字、中文词汇等分词处理,兼容韩文、日文字符 5.优化的词典存储,更小的内存占用。支持用户词典扩展定义。特别的,在2012版本,词典支持中文,英文,数字混合词语。源码下载地址:,该可下载源码和《IKAnalyzer中文分词器V2012使用手册.pdf》。
强烈建议将《IKAnalyzer中文分词器V2012使用手册.pdf》全部看完,之后应该对IKAnalyzer有比较全面的了解。
2.2、实例
实例步骤:
(1)下载IKAnalyzer2012.jar(),将IKAnalyzer2012.jar引入到java项目中。
(2)新建测试类:
package luo.test;import java.io.IOException;import java.io.StringReader;import org.wltea.analyzer.core.IKSegmenter;import org.wltea.analyzer.core.Lexeme;public class IKTest { public static void main(String[] args) throws IOException { String text = "IK Analyzer是一个结合词典分词和文法分词的中文分词开源工具包吗。它使用了全新的正向迭代最细粒度切分算法。"; //独立Lucene实现 StringReader re = new StringReader(text); IKSegmenter ik = new IKSegmenter(re,true); Lexeme lex = null; try { while((lex=ik.next())!=null){ System.out.print(lex.getLexemeText()+"|"); } }catch (Exception e) { // TODO: handle exception } } } (3)运行结果:

三、Ansj
3.1、介绍
Ansj中文分词
这是一个ictclas的java实现.基本上重写了所有的数据结构和算法.词典是用的开源版的ictclas所提供的.并且进行了部分的人工优化
内存中中文分词每秒钟大约100万字(速度上已经超越ictclas)
文件读取分词每秒钟大约30万字
准确率能达到96%以上
目前实现了.中文分词. 中文姓名识别 . 用户自定义词典
可以应用到自然语言处理等方面,适用于对分词效果要求高的各种项目.
3.2、实例
(1)下载ansj_seg-20130808 .jar(),将ansj_seg-20130808 .jar引入到java项目中。
(2)创建测试类:
package com.luo.test;import java.io.IOException;import java.io.StringReader; import org.ansj.domain.Term; import org.ansj.splitWord.Analysis; import org.ansj.splitWord.analysis.ToAnalysis; public class Test { public static void main(String[] args) throws IOException { Analysis udf = new ToAnalysis(new StringReader("Ansj中文分词是一个真正的ict的实现.并且加入了自己的一些数据结构和算法的分词.实现了高效率和高准确率的完美结合!")); Term term = null ; while((term=udf.next())!=null){ System.out.print(term.getName()+" "); } }} (3)运行结果:

四、Jcseg
4.1、介绍
jcseg是使用Java开发的一款开源的中文分词器, 使用mmseg算法. 分词准确率高达98.4%, 支持中文人名识别, 同义词匹配, 停止词过滤…, 详情请查看jcseg官方首页.
官方首页:
下载地址:Jcseg详细功能介绍: (可以略过, 方便查看新版本功能变化)
1。目前最高版本:jcseg-1.9.2。兼容最高版本lucene-4.x和最高版本solr-4.x 2。mmseg四种过滤算法,分词准确率达到了98.41%。 3。支持自定义词库。在lexicon文件夹下,可以随便添加/删除/更改词库和词库内容,并且对词库进行了分类。参考下面了解如何给jcseg添加词库/新词。 4。(!New) 支持词库多目录加载. 配置lexicon.path中使用’;’隔开多个词库目录. 5。(!New)词库分为简体/繁体/简繁体混合词库: 可以专门适用于简体切分, 繁体切分, 简繁体混合切分, 并且可以利用下面提到的同义词实现,简繁体的相互检索, jcseg同时提供了词库两个简单的词库管理工具来进行简繁体的转换和词库的合并. 6。中英文同义词追加/ 同义词匹配+ 中文词条拼音追加.词库整合了《现代汉语词典》和cc-cedict辞典中的词条,并且依据cc-cedict词典为词条标上了拼音,依据《中华同义词词典》为词条标上了同义词(尚未完成)。更改jcseg.properties配置文档可以在分词的时候加入拼音和同义词到分词结果中。jcseg 新版词库 7。中文数字和中文分数识别,例如:”一百五十个人都来了,四十分之一的人。”中的”一百五十”和”四十分之一”。并且jcseg会自动将其转换为阿拉伯数字加入到分词结果中。如:150 ,1/40。……….,详情可到官网下载文档《Jcseg-开发帮助文档.pdf》
4.2、实例
下载Jcseg:,博主下载的是:jcseg-1.9.2-src-jar-dict。
解压后,jcseg-1.9.2-src-jar-dict\jcseg-1.9.2目录下,我们需要用到的有三个:lexicon(里面包含分词用到的词库)、jcseg-core-1.9.2.jar、jcseg.properties。
实例步骤:
(1)将jcseg-core-1.9.2.jar引入到对应java项目。
(2)修改jcseg.properties的lexicon.path为lexicon(词库)的位置,如下,记得是正斜杠:
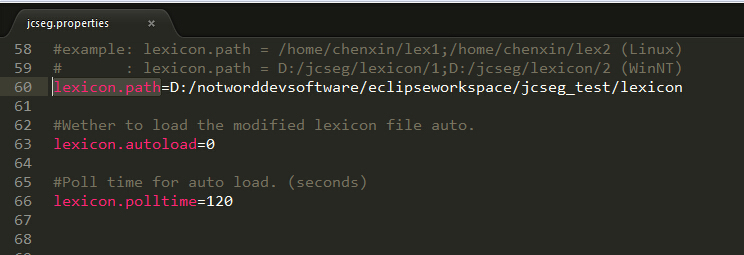
(3)创建测试类,注意修改代码类对应的路径:
package com.luo;import java.io.IOException; import java.io.StringReader; import org.lionsoul.jcseg.ASegment; import org.lionsoul.jcseg.core.ADictionary; import org.lionsoul.jcseg.core.DictionaryFactory; import org.lionsoul.jcseg.core.IWord; import org.lionsoul.jcseg.core.JcsegException; import org.lionsoul.jcseg.core.JcsegTaskConfig; import org.lionsoul.jcseg.core.SegmentFactory; public class Test { public static void main(String[] args) throws IOException, JcsegException { //创建JcsegTaskConfig分词任务实例 //即从jcseg.properties配置文件中初始化的配置 JcsegTaskConfig config = new JcsegTaskConfig("D:/notworddevsoftware/eclipseworkspace/jcseg_test/jcseg.properties"); //config.setAppendCJKPinyin(true); //创建默认词库(即: com.webssky.jcseg.Dictionary对象) //并且依据给定的JcsegTaskConfig配置实例自主完成词库的加载 ADictionary dic = DictionaryFactory .createDefaultDictionary(config,true); dic.loadFromLexiconFile("D:/notworddevsoftware/eclipseworkspace/jcseg_test/lexicon/lex-main.lex");//这个路径是jcseg-1.9.4-src-jar-dict.zip 这个jar 包的 存放路径, 你自己找lexicon 文件夹下的 lex-main.lex //依据给定的ADictionary和JcsegTaskConfig来创建ISegment //通常使用SegmentFactory#createJcseg来创建ISegment对象 //将config和dic组成一个Object数组给SegmentFactory.createJcseg方法 //JcsegTaskConfig.COMPLEX_MODE表示创建ComplexSeg复杂ISegment分词对象 //JcsegTaskConfig.SIMPLE_MODE表示创建SimpleSeg简易Isegmengt分词对象. ASegment seg = (ASegment) SegmentFactory.createJcseg(JcsegTaskConfig.COMPLEX_MODE,new Object[]{config, dic}); //设置要分词的内容 String str = "jcseg是使用Java开发的一款开源的中文分词器, 使用mmseg算法. 分词准确率高达98.4%."; seg.reset(new StringReader(str)); //获取分词结果 IWord word = null; while ( (word = seg.next()) != null ) { System.out.print(word.getValue() + "|"); } } } (4)运行结果:

五、自己使用算法实现
上面IKAnalyzer、Ansj、Jcseg都是java开源项目,可根据自己的个性化需求修改源码。
当然,其实也是可以自己写算法实现的。下面是博主之前看过的一篇文章,非常详细清晰的思路:。
六、词库推荐
分词基本都是基于词库实现的,下面博主推荐一个词库,搜狗输入法细胞库,里面词库很全面,而且已经分好类,比如如果是商品搜索引擎,在里面寻找相关词库,有助于提高准确度哦:
下载下来的词库是.scel格式的,猿友可以使用“深蓝细胞词库scel转txt工具”进行转换。